V předešlé hodině jsme se vyhýbali programování, jak jen se to dalo. Teď už si ale chceš také sama vše vyzkoušet. Abys mohla úlohu rozmyšlenou v domácím úkolu naprogramovat, projdeme si nejdůležitější funkce, které budeš potřebovat. Použijeme jednoduchá data salaries.csv
Především budeme používat knihovnu Scikit-learn a samozrejmě také pandas. Potřebné věci projdeme na příkladu.
import pandas as pd
import numpy as np
np.random.seed(42)Načtení a příprava dat¶
☑ výběr vstupních proměnných a výstupu ☑ rozdělení na trénovací a testovací data ☑ chybějící hodnoty ☑ kategorické hodnoty ☑ přeškálování / normování hodnot |
Na začátku vždy bude potřeba připravit data. Čištění dat a použití knihovny pandas už bys měla ovládat, zaměříme se jen na věci, které jsou specifické pro strojové učení.
Načíst data tedy umíš.
df_salary = pd.read_csv("static/salaries.csv", index_col=0)
df_salary.sample(10)Pro přehlednost si data přeložme do češtiny.
df_salary = (
df_salary
.rename(columns={"discipline": "disciplina",
"yrs.since.phd": "delka_praxe",
"yrs.service": "delka_zamestnani",
"sex": "pohlavi",
"salary": "plat"})
.replace({"Male": "muž",
"Female": "žena",
"Prof": "profesor",
"AssocProf": "docent",
"AsstProf": "asistent"})
)
df_salaryVytvoření trénovací a testovací množiny¶
Pro predikci použijeme jako příznaky rank, disciplina, delka_praxe, delka_zamestnani a pohlavi,
predikovat budeme hodnotu plat.
V teorii strojového učení se vstupy modelu (příznaky, vstupní proměnné) typicky označují písmenem X a výstupy písmenem y. Řada programátorů toto používá i k označování proměnných v kódu.
X představuje matici (neboli tabulku), kde každý řádek odpovídá jednomu datovému vzorku a každý sloupec jednomu příznaku (vstupní proměnné). y je vektor, neboli jeden sloupec s odezvou.
(Na vyzobnutí odezvy se může hodit metoda pop. Její nevýhodou je ale nemožnost opakovaně spouštět buňku.)
y = df_salary["plat"]
X = df_salary.drop(columns=["plat"])
print(X.columns)
print(y.name)Index(['rank', 'disciplina', 'delka_praxe', 'delka_zamestnani', 'pohlavi'], dtype='object')
plat
X.head()y.head()1 139750
2 173200
3 79750
4 115000
5 141500
Name: plat, dtype: int64Zbývá data rozdělit na trénovací a testovací, to je třeba udělat co nejdříve, abychom při různých konverzích dat používali jen informace z trénovací množiny a testovací množina byla opravdu jen k evaluaci. K tomu slouží metoda train_test_split.
Data nám rozdělí náhodně na trénovací a testovací sadu. Velikost testovací množiny můžeme specifikovat parametrem test_size, jeho defaultní hodnota je 0.25, t. j. 25%.
from sklearn.model_selection import train_test_split
#X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y)
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, test_size=0.3)X_train_rawKódování vstupů¶
Pro učení potřebujeme všechny hondoty převést na čísla (float). Pokud by data obsahovala chybějící
hodnoty, nejjednodušší řešení je takové řádky zahodit. (Bonus: pokud bys měla data s větším množstvím
chybějících hodnot, podívej se na možnosti sklearn.impute)
Dále je důležité vypořádat se s kategorickými hodnotami. Sloupce obsahující hodnoty typu Boolean nebo dvě hodnoty (např. muž/žena), lze snadno převést na hodnoty .
Pro kategorické proměnné s více možnostmi použijeme tzv. onehot encoding.
Např. sloupec rank obsahuje hodnoty profesor, docent a asistent. K zakódování pomocí onehot encoding potřebujeme tři sloupce:
| Původní hodnota | Kód |
|---|---|
| profesor | 1 0 0 |
| docent | 0 1 0 |
| asistent | 0 0 1 |
Knihovna Scikitlearn nabízí sklearn
Při práci s pandas se může hodit i metoda get_dummies. (Pozn. dummies proto, že nám přibudou pomocné proměnné (sloupce), které se označují jako dummy variables.) Ale pozor, pokud budeme později potřebovat stejným způsobem zakódovat další data, musí obsahovat stejné kategorie.
pd.get_dummies(X_train_raw).head()Naše data zakódujeme pomocí OneHotEncoder z knihovny Scikit-learn.
OneHotEncoder si představ jako krabičku, která má vstupy a výstupy (podobně jako model strojového učení), a vstupy nějak transformuje na výstupy. Každá takováto krabička, která slouží pro přípravu (transformaci) dat, má metody:
- fit
- transform
- fit_transform
Metoda fit slouží k inicializaci krabičky, nastavení na daná data. Metoda transform pak je samotný běh krabičky, provádí transformaci dat. Metoda fit_transform na daných datech krabičku inicializuje a poté data i transformuje.
Rozdělme si sloupečky (vstupní proměnné) podle datových typů.
categorical_columns = ["rank", "disciplina"]
numerical_columns = ["delka_praxe", "delka_zamestnani"]
boolean_columns = ["pohlavi"]Kategorické proměnné zakódujme pomocí one-hot kódování.
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoder.fit(X_train_raw[categorical_columns])
# zeptejme se encodéru na jména nových proměnných (sloupečků)
column_names = encoder.get_feature_names_out()column_namesarray(['rank_asistent', 'rank_docent', 'rank_profesor', 'disciplina_A',
'disciplina_B'], dtype=object)encoder.transform(X_train_raw[categorical_columns])<Compressed Sparse Row sparse matrix of dtype 'float64'
with 276 stored elements and shape (138, 5)>Metoda transform nám vrátila objekt s řídkou maticí, která se hodí pro data zakódovaná pomocí one-hot kódování. My chceme data i přehledně vidět, proto zde použijeme parametr sparse_output a řídký výstup vypneme.
encoder1 = OneHotEncoder(sparse_output=False)
encoder1.fit(X_train_raw[categorical_columns])
encoder1.transform(X_train_raw[categorical_columns])array([[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 1., 0., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 1., 0., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 1., 0.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 1., 0.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 0., 1., 0., 1.],
[0., 1., 0., 0., 1.],
[0., 0., 1., 0., 1.],
[1., 0., 0., 1., 0.],
[0., 1., 0., 1., 0.],
[1., 0., 0., 1., 0.]])Umíme tedy vytvořit krabičku, která transformuje data. Zatím jsme jí dávali vybrané sloupce, nyní si pojďme ukázat, jak několik takových krabiček (každou pro jeden typ vstupů) poskládat dohromady do jedné velké krabičky, která umí transformovat celá data (všechny sloupce).
Začneme vytvořením krabičky, která kategorické sloupce zakóduje pomocí one-hot kódování a všechny ostatní nechá v původním stavu.
from sklearn.compose import make_column_transformertransformer = make_column_transformer(
# parameter handle_unkown ignore říká, že pokud při transformaci narazíme na neznámou hodnotu,
# transformace neskončí chybou, ale hodnota se zakóduje pomocí samých 0
(OneHotEncoder(sparse_output=False, handle_unknown="ignore"),categorical_columns),
remainder="passthrough"
)transformer.fit(X_train_raw)
pd.DataFrame(transformer.transform(X_train_raw))transformer.get_feature_names_out()array(['onehotencoder__rank_asistent', 'onehotencoder__rank_docent',
'onehotencoder__rank_profesor', 'onehotencoder__disciplina_A',
'onehotencoder__disciplina_B', 'remainder__delka_praxe',
'remainder__delka_zamestnani', 'remainder__pohlavi'], dtype=object)Teď zbývá zakódovat sloupeček pohlaví, který nabývá dvou hodnot. Samozřejmě můžeme použít i one-hot encoding, ale chceme si ukázat i jiné kódování. Nabízí se použití OrdinalEncoder, který zakóduje hodnoty jako čísla 0 až N-1, kde N je počet tříd. Přidejme tento kodér do našeho velkého transformátoru.
from sklearn.preprocessing import OrdinalEncodertransformer = make_column_transformer(
(OneHotEncoder(sparse_output=False), categorical_columns),
(OrdinalEncoder(), boolean_columns),
remainder="passthrough"
)X_train_transformed = transformer.fit_transform(X_train_raw)
X_test_transformed = transformer.transform(X_test_raw)column_names = transformer.get_feature_names_out()
pd.DataFrame(X_test_transformed, columns=column_names).head(10)Škálování¶
Přeškálování není vždy nutné, ale některým modelům to může pomoci. Řiďte se tedy pravidlem, že rozhodně neuškodí. Využijeme StandardScaler.
StandardScaler nám hodnoty přeškáluje, aby zhruba odpovídaly normálnímu rozdělení. Některé algoritmy (na učení) to předpokládají. Pokud bychom neškálovali, mohlo by se stát, že příznak (sloupeček), která má výrazně větší rozptyl než ostatní, je brán jako významnější.
Nejprve si ukažme jednoduchý příklad. Vygenerujeme si dva sloupečky náhodných bodů, každý jiným způsobem.
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import seaborn as sns
# vygeneruje 100 náhodných bodů
example = pd.DataFrame({"a": 100+np.random.randn(100), "b": 100*np.random.randn(100)})
example.head(20)Podívejme se, jak sloupečky vypadají. Ve sloupci a máme hodnoty s malým rozptylem kolem 100 a ve sloupci b čísla s velkým rozptylem a průměrem v nule.
example.describe()Data nyní přeškálujeme pomocí StandardScaler a podíváme se, jak vypadají původní a přeškálovaná data.
example_scaler = StandardScaler()
transformed_example = example_scaler.fit_transform(example)
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(10, 4))
ax1.set_title("Histogram původních dat")
sns.histplot(example, ax=ax1)
ax2.set_title("Histogram přeškálovaných dat")
sns.histplot(transformed_example, ax=ax2);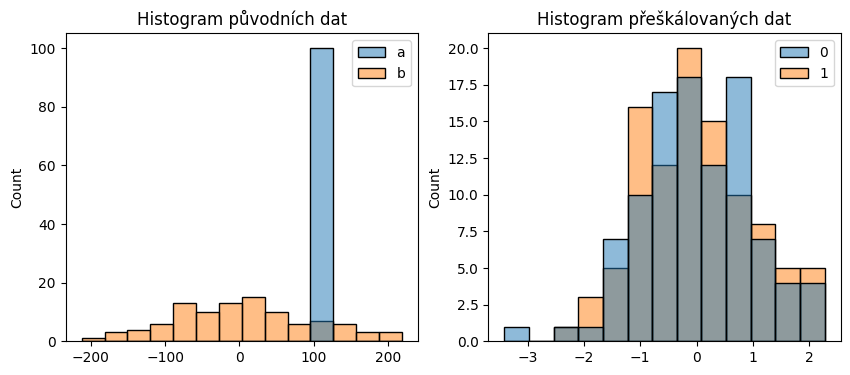
pd.DataFrame(transformed_example).describe()pd.DataFrame(transformed_example).head()Zpátky k našim datům o platech. Transformaci musíme nastavit (fit) pouze na trénovacích datech, škálovat pak budeme stejným způsobem trénovací i testovací data.
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train_transformed)
X_test = scaler.transform(X_test_transformed)
pd.DataFrame(X_train, columns=column_names).sample(10)Máme tedy připraveny dvě krabičky, transformer a scaler. První data převede na numerické hodnoty, druhá je přeškáluje.
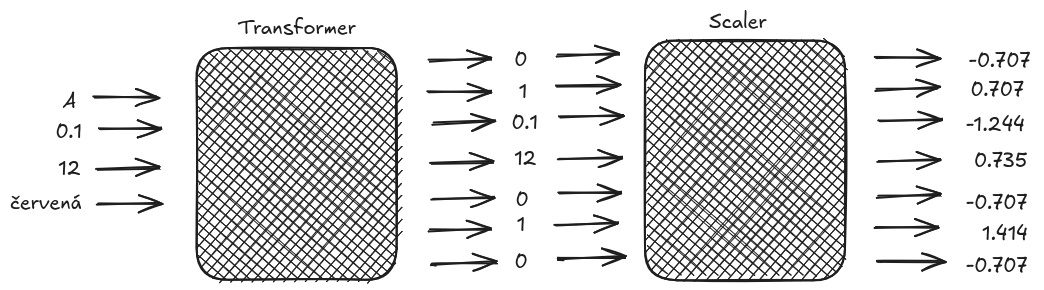
Modely¶
Můžeme přejít k samotnému učení. Data máme připravena, nyní chceme za připravené krabičky zapojit model, který bude generovat požadovanou predikci.

Vybereme si model. Přehled modelů najdeš v sekci Supervised learnig.
Na regresi můžeš použít:
- hyperparametry:
- alpha, float, default=1.0
- hyperparametry:
- hyperparametry:
- kernel, default rbf, one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’
- C, float, optional (default=1.0)
- hyperparametry:
Na klasifikační úlohy (ke kterým se dostaneme v příští hodině) využiješ:
- hyperparametry:
- n_estimators, integer, optional (default=100)
- hyperparametry:
- hyperparametry:
- C, float, optional (default=1.0)
- kernelstring, optional (default=’rbf’)
- hyperparametry:
Tyto krabičky, modely, mají metody fit a predict. fit slouží pro učení, předáme jí trénovací data a krabička se na nich naučí. Naučenou krabičku pak můžeme používat k predikcím na nových datech pomocí predict.
Protože teď jde jen o způsob použití knihovny, vezmeme nejjednodušší lineární regresi):
from sklearn.linear_model import LinearRegression
model = LinearRegression()modelTrénování¶
Model natrénujeme na trénovací množině:
model.fit(X_train, y_train)Predikce¶
Natrénovaný model typicky chceme použít k ohodnocení nějakých nových datových vzorků, k tomu máme metodu predict. Zavolejme ji jak na trénovací, tak na testovací data.
train_predikce = model.predict(X_train)
test_predikce = model.predict(X_test)Přidejme predikce vedle vstupního DataFramu a podívejme se na několik testovacích vzorků a jejich predikce:
(
X_test_raw
.assign(plat=y_test)
.assign(predikce=test_predikce)
).sample(15)Jednoduchý dotaz¶
Vyzkoušejte si zadat modelu svůj vlastní jednoduchý dotaz. K tomu můžete využít následující jednořádkový DataFrame.
dotaz = pd.DataFrame({
"rank": "profesor",
"disciplina": "B",
"delka_praxe": 30,
"delka_zamestnani": 10,
"pohlavi": "muž",
}, index=[0])
dotazNyní musíme naše nová data ztransformovat stejně, jako jsme to dělali s trénovacími a testovacími daty:
X_query = scaler.transform(transformer.transform(dotaz))
X_queryarray([[-0.51580524, -0.52704628, 0.86419641, -0.58292866, 0.58292866,
-0.39957961, 0.95005911, -0.44338446]])print(f"Odhadovaný plat vašeho pracovníka je: {model.predict(X_query)[0]:.2f}")Odhadovaný plat vašeho pracovníka je: 132266.46
Evaluace modelu¶
Můžeme využít funkci score, která nám vrátí hodnotu metriky:
print("R2 na trénovací množině: ", model.score(X_train, y_train))
print("R2 na testovací množině: ", model.score(X_test, y_test))R2 na trénovací množině: 0.5595836894676703
R2 na testovací množině: 0.44012547896345444
Funkce pro všechny možné metriky najdeš v sklearn.metrics. (nyní nás zajímají regresní metriky)
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
MAE_train = mean_absolute_error(y_train, train_predikce)
MAE_test = mean_absolute_error(y_test, test_predikce)
MSE_train = mean_squared_error(y_train, train_predikce)
MSE_test = mean_squared_error(y_test, test_predikce)
R2_train = r2_score(y_train, train_predikce)
R2_test = r2_score(y_test, test_predikce)
print(" Trénovací data Testovací data")
print(f"MSE {MSE_train:>14.3f} {MSE_test:>14.3f}")
print(f"MAE {MAE_train:>14.3f} {MAE_test:>14.3f}")
print(f"R2 {R2_train:>14.3f} {R2_test:>14.3f}") Trénovací data Testovací data
MSE 371323242.638 418020527.179
MAE 13499.748 15155.533
R2 0.560 0.440
Porovnání s baseline¶
Pro jednoduché zjištění, zda se model něco naučil, můžeme použít baseline řešení připravené v knihovně Scikit-learn, a jím je DummyRegressor.
from sklearn.dummy import DummyRegressor
baseline = DummyRegressor()
baseline.fit(X_train, y_train)
print("R2 na trénovací množině: ", baseline.score(X_train, y_train))
print("R2 na testovací množině: ", baseline.score(X_test, y_test))
train_pred = baseline.predict(X_train)
test_pred = baseline.predict(X_test)
print("MSE na trénovací množině: ", mean_squared_error(y_train, train_pred))
print("MSE na testovací množině: ", mean_squared_error(y_test, test_pred))R2 na trénovací množině: 0.0
R2 na testovací množině: -0.005743396511123988
MSE na trénovací množině: 843118735.0657951
MSE na testovací množině: 750920731.3776834
Uložení modelu¶
Někdy si potřebujeme naučený model uchovat na další použití. Model lze uložit do souboru a zase načíst pomocí pickle.
Kujme pikle:
import pickle
print(model.score(X_test, y_test))
# uložení modelu
with open("model.pickle", "wb") as soubor:
pickle.dump(model, soubor)
# načtení modelu
with open("model.pickle", "rb") as soubor:
staronovy_model = pickle.load(soubor)
staronovy_model.score(X_test, y_test)0.44012547896345444
0.44012547896345444Bonusy:¶
volba vhodného modelu a jeho hyper-parametrů se skrývá pod klíčovým slovem model selection. Knihovna Scikit-learn obsahuje různé pomůcky k ulehčení toho výběru. Přesahuje to ale rámec tohoto kurzu, narazíš-li na to toho téma při samostudiu, pročti si sklear
.model _selection. v příkladu výše jsme použili různé transformace nad daty a pak teprve tvorbu modelu. Až budeš v těchto věcech zběhlejší, bude se ti hodit propojit tyto věci dohromady. K tomu slouží tzv. pipeline.
from sklearn.pipeline import Pipelinepipe = Pipeline([
("transform", transformer),
("scaler", scaler),
("model", model)
])
pipepipe.fit(X_train_raw, y_train)test_prediction = pipe.predict(X_test_raw)
X_test_raw.sample(10)X_test_raw.assign(plat=y_test).assign(predikce=test_predikce).sample(10)