Stáhněte si pracovní notebook, projděte si jej a vyplňte všechny úkoly. Poté si svá řešení porovnejte s řešeními v tomto notebooku.
import pandas as pd
import numpy as np
# učení modelů obsahuje určitou náhodnost
# nastavením random.seed zaručíme všem stejné výsledky
np.random.seed(42) # sklearn rádo vypisuje různé warningy během učení modelu, např. že učení nechce zkonvergovat
# ač tato informace je důležitá, nyní se tím nechceme rozptylovat a tyto warningy vypneme
import warnings
from sklearn.exceptions import ConvergenceWarning
warnings.filterwarnings("ignore", category=ConvergenceWarning)- Načtěte si data pomocí pandas, vyberte požadované sloupce, které budete používat.
def read_fish_data(filename):
return (
pd.read_csv(filename, index_col=0)
.rename(columns={
"Species": "druh",
"Weight": "vaha",
"Length1": "delka1",
"Length2": "delka2",
"Length3": "delka3",
"Height": "vyska",
"Width": "sirka"})
.replace({
"Bream": "Cejn",
"Parkki": "Parma",
"Perch": "Okoun",
"Pike": "Štika",
"Roach": "Plotice",
"Smelt": "Šprota",
"Whitefish": "Síh"})
)fish_data = read_fish_data("fish_data.csv")
fish_data = fish_data.drop(columns=["ID"])
fish_dataInstrukce:
V úkolech už je předpřipraven kód, stačí když doplníte tam, kde jsou ... nebo ____.
Úkol 1: výběr vstupů a výstupů, rozdělení na trénovací a testovací data¶
- Zvol si sloupec, který budeš používat jako odezvu (vaha). Do proměnné X ulož sloupce, které budeš používat jako příznaky, do proměnné y sloupec s odezvou.
V teorii strojového učení se vstupy modelu (příznaky, vstupní proměnné) typicky označují písmenem X a výstupy písmenem y. Takto se často označují i proměnné v kódu. X představuje matici (neboli tabulku), kde každý řádek odpovídá jednomu datovému vzorku a každý sloupec jednomu příznaku (vstupní proměnné). y je vektor, neboli jeden sloupec s odezvou.
y = fish_data["vaha"]
X = fish_data.drop(columns=["vaha"])- Rozděl data na trénovací a testovací. Všimni si, že máme v datech různé druhy ryb, na co si dát pozor?
Metoda train_test_split nám data rozdělí náhodně na trénovací a testovací sadu. Velikost testovací množiny můžeme specifikovat parametrem test_size, jeho přednastavená (default) hodnota je 0.25, t. j. 25%.
from sklearn.model_selection import train_test_split
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, stratify=X["druh"])Úkol 2: převeď data na numerické hodnoty a přeškáluj je¶
- Překóduj potřebné sloupce pomocí OneHotEncoding.
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import make_column_transformer
categorical_columns = ["druh"]
transformer = make_column_transformer(
(OneHotEncoder(sparse_output=False), categorical_columns),
remainder="passthrough"
)
X_train_onehot = transformer.fit_transform(X_train_raw)
X_test_onehot = transformer.transform(X_test_raw)
pd.DataFrame(X_train_onehot, columns=transformer.get_feature_names_out())- Přeškáluj sloupce pomocí StandardScaler.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train_onehot)
X_train = scaler.fit_transform(X_train_onehot)
X_test = scaler.transform(X_test_onehot)Odbočka: co jsou to ty hyper-parametry?¶
U příkladů s černými krabičkami v první hodině jsme si (za vašimi zády) několikrát trochu pomohli a krabičce jsme předali na začátku nějaké parametry. Krabička totiž často umožňuje uživateli, aby si ji nakonfiguroval. V terminologii krabiček si můžeme představit, že krabička má na sobě různé páčky, kterými se dá seřídit. Těmito páčkami se nastavují tzv. hyper-parametry modelu. Všechny modely, které najdeš v knihovně Scikit-learn, mají nějaké výchozí nastavení a půjdou použít i bez toho, aby ses nastavením těchto hyper-parametrů zabývala. V případě, že model nedává uspokojivý výsledek, můžeš zkusit tyto parametry upravit, např. vyzkoušet několik různých nastavení a porovnat hodnotu metriky na testovací množině.
U seznamu výše máme některé hyperparametry uvedené. Parametry často souvisejí s regularizací (výše alpha, C). Regularizace znamená, že model kromě toho, že se snaží nafitovat tak, aby odpovídal datům (dával správné odpovědi), zohledňuje nějaké další kriterium. Typicky toto kritérium hlídá, aby výstup modelu moc neosciloval, apod. Podobně jako jsi v příkladu s krajinou říkala, že řešení volíš tak, aby bylo plynulé, hezké, odpovídalo obvyklým krajinám.
Proces výběru modelu včetně jeho parametrů se nazývá model selection, v knihovně Scikit-learn najdeš nástroje, které ti mohou pomoci, pod heslem Model selection.
Úkol 3: výběr modelu a učení¶
- Vyber si několik regresních modelů a zkus je použít.
Pro dnešek možno zkusit:
- hyperparametry:
- alpha, float, default=1.0
- hyperparametry:
- hyperparametry:
- kernel, default rbf, one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’
- C, float, optional (default=1.0)
- hyperparametry:
from sklearn.linear_model import LinearRegression, Lasso
from sklearn.svm import SVRmodel_zoo = {
"linear_regression": LinearRegression(),
"lasso_var1": Lasso(alpha=1.0),
"lasso_var2": Lasso(alpha=1e-03),
"SVR_rbf": SVR(kernel="rbf", C=1e04),
"SVR_poly": SVR(kernel="poly",C=1e04),
}- K trénovaní (fitování) slouží metoda
fit, k predikci pro nové vzory metodapredict.
model.fit(X_train, y_train)
pred = model.predict(X_test)- Metriku nemusíš programovat, k dispozici máš
mean_absolute_error,mean_squared_errorar2_score.
metrika = mean_absolute_error(y_test, pred)from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
def fit_and_eval(X_train, y_train, X_test, y_test, model, name):
""" 1. Natrénuje model na trénovací množině.
2. Spočte hodnoty metrik na trénovací i testovací množině.
vrátí slovník ve tvaru {"název metriky": hodnota}
"""
print("Zpracovávám model", name)
model.fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
return {
"MAE_train": mean_absolute_error(y_train, y_train_pred),
"MSE_train": mean_squared_error(y_train, y_train_pred),
"MAE_test": mean_absolute_error(y_test, y_test_pred),
"MSE_test": mean_squared_error(y_test, y_test_pred),
"r2_score_train": r2_score(y_train, y_train_pred),
"r2_score_test": r2_score(y_test, y_test_pred),
}results = []
for name, model in model_zoo.items():
result = fit_and_eval(X_train, y_train, X_test, y_test, model, name)
result["model"] = name
results.append(result)
pd.DataFrame(results)Úkol 4: výběr modelu¶
Naučili jsme několik modelů. Zamysli se teď na chvilku, který by sis vybrala a proč.
Označme si jej jako best_model. Můžeš si i zkusit pohrát s hyperparametry a zvolit jiné nastavení.
# doplň jméno modelu, který jsi vybrala
best_model = model_zoo["SVR_rbf"]A pozor, překvapení ... další testovací množina¶
Data jsme si rozdělili na trénovací a testovací. Trénovací jsme použili na učení modelu. Ale pozor! Testovací množinu jsme použili k výběru modelu. Metrika na testovací množině nám tedy nedává nezávislý odhad toho, jak se bude náš model chovat na neznámých datech. Byl totiž vybrán tak, aby dával dobré výsledky na testovací množině.
Testovací množina nám slouží jako odhad generalizačních schopností modelu. Neměla by ale být použita ani při učení, ani při výběru modelu. Část, kterou si oddělíme na “testování” pro účely výběru modelu, nazýváme správně validační množina. Pozor: Pokud jsme ale tuto validační množinu použili k výběru modelu, nesmíme ji používat k samotnému hodnocení generalizačních schopností tohoto modelu.
A proto teď přichází opravdová testovací data, načtěte je ze souboru fish_data_test.csv.
test_data = read_fish_data("fish_data_test.csv")
test_data.pop("ID")
y_real_test = test_data.pop("vaha")
X_real_test_raw = test_data
X_real_test_transformed = transformer.transform(X_real_test_raw)
X_real_test = scaler.transform(X_real_test_transformed)y_pred_test = best_model.predict(X_real_test)
print(f"MAE {mean_absolute_error(y_real_test, y_pred_test):.3f}")
print(f"MSE {mean_squared_error(y_real_test, y_pred_test):.3f}")
print(f"R2 {r2_score(y_real_test, y_pred_test):.3f}")MAE 41.858
MSE 6432.307
R2 0.956
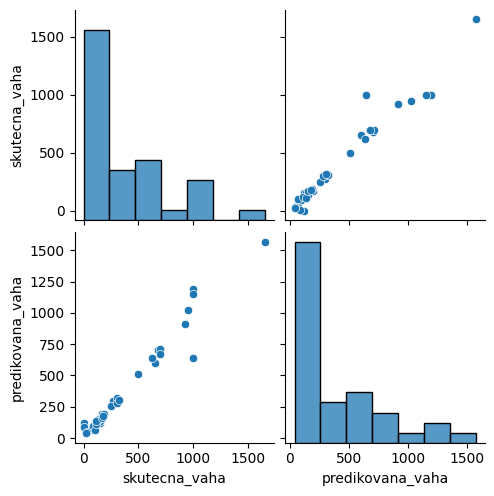
data_with_pred = X_real_test_raw.assign(skutecna_vaha=y_real_test).assign(predikovana_vaha=y_pred_test)
data_with_predVisualizace na závěr¶
- Pro představu si zobrazme závislost váhy ryby na délce
delka3. Zobrazíme zvlášt pro různé druhy, tedy např. pro cejny (bream) a plotice (roach).
is_bream = X_real_test_raw["druh"] == "Cejn"
predicted_bream_weights = best_model.predict(X_real_test[is_bream])
is_roach = X_real_test_raw["druh"] == "Plotice"
predicted_roach_weights = best_model.predict(X_real_test[is_roach])result_bream = pd.DataFrame()
result_bream["delka"] = X_real_test_raw[is_bream]["delka3"]
result_bream["skutecna_vaha"] = y_real_test[is_bream]
result_bream["predikovana_vaha"] = predicted_bream_weights
result_bream = result_bream.sort_values("delka")
result_roach = pd.DataFrame()
result_roach["delka"] = X_real_test_raw[is_roach]["delka3"]
result_roach["skutecna_vaha"] = y_real_test[is_roach]
result_roach["predikovana_vaha"] = predicted_roach_weights
result_roach = result_roach.sort_values("delka")
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 2)
ax[0].plot(result_bream["delka"], result_bream["skutecna_vaha"], label="skutecnost", marker="o");
ax[0].plot(result_bream["delka"], result_bream["predikovana_vaha"], label="predikce", marker="o");
ax[0].legend()
ax[0].set_title("Cejn")
ax[1].plot(result_roach["delka"], result_roach["skutecna_vaha"], label="skutecnost", marker="o");
ax[1].plot(result_roach["delka"], result_roach["predikovana_vaha"], label="predikce", marker="o");
ax[1].legend()
ax[1].set_title("Roach");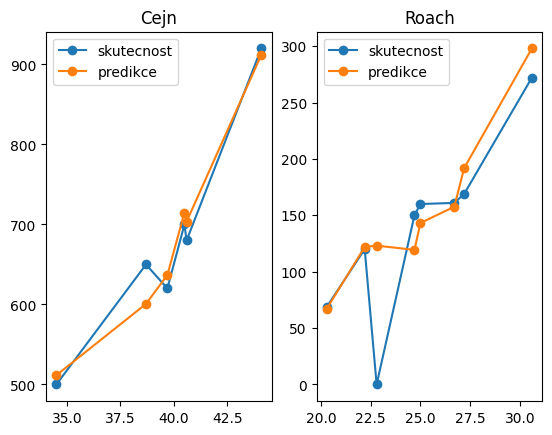
import seaborn as sns
sns.pairplot(data_with_pred[["skutecna_vaha", "predikovana_vaha"]]);