Zatím jsme se zabývali jen regresními úlohami. Učení s učitelem (supervised learning) ale zahrnuje dvě hlavní skupiny úloh - regresní úlohy a klasifikační úlohy.
Zatímco u regresních úloh je výstupem modelu spojitá hodnota (float), v klasifikačních úlohách představuje výstup modelu indikátor třídy (label).
Držme se našeho rybího trhu a ukažme si to na příkladu. Úloha predikovat váhu ryby byla regresní úloha, predikovali jsme spojitou hodnotu. Pokud budeme chtít predikovat druh ryby (okoun - perch, plotice - roach, štika - pike, ...), jedná se o predikci kategorické hodnoty, tedy o klasifikaci.
Klasifikační úlohy mají trochu jiné vlastnosti a logiku než úlohy regresní, proto existují modely přímo určené na takové úlohy. Říká se jim klasifikátory.
Zkusíme se ale nejdřív podívat na úlohu klasifikace z pohledu, který už známe, tedy z pohledu krajiny.
# načeteme si data
import pandas as pd
import numpy as np
np.random.seed(2020) # nastavení náhodného klasifikátoru
def read_fish_data(filename):
return (
pd.read_csv(filename, index_col=0)
.rename(columns={
"Species": "druh",
"Weight": "vaha",
"Length1": "delka1",
"Length2": "delka2",
"Length3": "delka3",
"Height": "vyska",
"Width": "sirka"})
.replace({
"Bream": "Cejn",
"Parkki": "Parma",
"Perch": "Okoun",
"Pike": "Štika",
"Roach": "Plotice",
"Smelt": "Šprota",
"Whitefish": "Síh"})
)
data = read_fish_data("static/fish_data.csv")
data.sample(10)data.groupby("druh")["druh"].count().sort_values(ascending=False)druh
Okoun 42
Cejn 29
Štika 15
Šprota 13
Plotice 12
Parma 8
Síh 4
Name: druh, dtype: int64Úkol 1:¶
Nejčastějším druhem ryby je Okoun. Naším cílem je vytvořit klasifikátor, který pro zadané míry (váha, různé délky a šířky) vrátí informaci, zda se jedná o okouna nebo jiný druh. (Máme tedy pro jednoduchost jen dvě třídy, Okoun a ostatní.)
Uměla bys tuto úlohu napasovat na krajinu? Co by mohly být souřadnice a co nadmořská výška?
Pokud ses úspěšně poprala s předchozím dotazem, můžeš na klasifikaci použít některý z regresních modelů (ano, asi to nebude ideální, když jde o klasifikaci, ale zkusme nejdříve to, co již umíme). Co ale bude hodnota odezvy a jak ji budeme interpretovat?
Odpovědí na tyto otázky je použití lineární regrese na klasifikační úlohu v bonusovém materiálu.
Klasifikační modely¶
Přinášíme opět nějakou základní nabídku klasifikačních modelů:
- n_estimators, integer, optional (default=100)
- C, float, optional (default=1.0)
- kernel,string, optional (default=’rbf’)
Úkol 2:¶
Vyberete si jeden model a zkuste natrénovat na ryby.
Nejprve připravíme data obdobně jako v minulé hodině. Jako sloupeček odezvy použijeme True pro okouny a False pro ostatní ryby. Sloupeček druh pak už nebudeme potřebovat, stejně tak můžeme vypustit sloupeček ID.
# připravme data
y = data["druh"] == "Okoun"
X = data.drop(columns=["ID", "druh"])Dalším krokem je rozdělení na trénovací a validační data. Nezapomeňme na stratifikaci.
# rozdělme na trénovací a validační množinu
from sklearn.model_selection import train_test_split
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, stratify=y)Podívejme se jaké je zastoupení okounů v trénovací a testovací množině (díky stratifikaci by mělo být procento okounů v obouch datasetech přibližně stejné).
print(f"Trainset: {100 * y_train.sum()/len(y_train):.0f}%")
print(f"Testset: {100 * y_test.sum()/len(y_test):.0f}%")Trainset: 34%
Testset: 35%
Vstupní data už obsahují jen numerické hodnoty, ale raději je ještě přeškálujeme.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train_raw)
X_test = scaler.transform(X_test_raw)Jako model zvolíme rozhodovací strom. Neboj se ale zkusit jiný klasifikátor dle své volby.
# vytvořme instanci třídy DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model# natrénujte
model.fit(X_train, y_train);Máme natrénovaný model, jdeme se podívat, jak funguje na validačních datech.
# ohodnoťme validační množinu
pred = model.predict(X_test) df_compare = (
X_test_raw
.assign(druh=y_test)
.assign(predikce=pred)
)
df_compare["spravne"] = (df_compare["druh"] == df_compare["predikce"]).replace({True: "OK", False: ":("})
df_compare = df_compare.replace({True: "Okoun", False: "Ostatní"})
display(df_compare.sample(10))
print(f"Počet chyb ve validačních datech: {sum(y_test != pred)}")Úkol 3:¶
- Asi je jasné, že regresní metriky se nám na klasifikační úlohy moc nehodí. Zamysli se, co bys použila jako metriku pro klasifikační úlohu.
Úkol 4:¶
- Jedna z možností je porovnávat procento úspěšně klasifikovaných vzorů. V našem případě, to bude:
print(f"Úspěšnost: {100*sum(y_test == pred)/len(y_test):.2f} %")Úspěšnost: 93.55 %
Úspěšnost není úplně špatná, poznat druh ryby podle rozměrů není jednoduchá úloha.
Představ si ale, že budeme mít v datovou množinu se 100 rybami, 95 z nich bude okounů. Bude ti klasifikátor, který bude mít toto procento úspěšnosti (stejné jako vyšlo nám), připadat dobrý nebo ne? Proč?
Úkol 5:¶
Nejprve si projdeme klasifikační metriky. Pokud studuješ sama, nastuduj si kapitolu o klasifikačních metrikách a pak se vrať k tomuto cvičení.
Vyber si metriku pro naši úlohu a zkus najít, co nejlepší klasifikátor. Pak si načti testovací množinu a podívej se, jaké tvůj klasifikátor dává výsledky.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
# zkus naučit různé modely a vyber nejlepší
models = {}
# KNeigbors
for N in 1, 3, 5, 7:
models[("nearest neighbors", N)] = KNeighborsClassifier(n_neighbors=N, weights="distance")
# tree
for d in range(3, 20):
models[("tree", d)] = DecisionTreeClassifier(max_depth=d, class_weight='balanced')
# random forest
for N in range(1, 100, 2):
models[("random forest", N)] = RandomForestClassifier(n_estimators=N, class_weight='balanced')
# SVC
for C in range(-2, 10):
models[("SVC", 10**C)] = SVC(C=10**C, class_weight="balanced")Vytvořili jsme si slušnou zásobu modelů, uložili jsme je do slovníku. Každý model máme pro různé hodnoty příslušného hyper-parametru.
Všimni si i parametru class_weight, "balanced" zohlední různé počty vzorů v jednolivých třídách, t.j. máme-li 31 okounů a 61 ostatních, přiřadí třídě okounů větší důležitost (aby se vyrovala nerovnováha v počtu trénovacích vzorů).
Obdobně jako v minulé hodině vytvoříme funci, která ohodnotí model a vrátí hodnoty vybrané metriky na trénovací a validační množině. Hodnoty vrací ve slovníku (což nám pak umožní snadnější vytvoření dataframu s výsledky).
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
def train_and_eval(X_train, X_test, y_train, y_test, model):
model.fit(X_train, y_train)
y_pred_test = model.predict(X_test)
y_pred_train = model.predict(X_train)
return {
"train": f1_score(y_train, y_pred_train), # metriku můžeš vyměnit za nějakou svojí
"test": f1_score(y_test, y_pred_test)
}import tqdm
results = []
for name, model in tqdm.tqdm(models.items()):
res = train_and_eval(X_train, X_test, y_train, y_test, model)
res["model"] = name[0]
res["param"] = name[1]
results.append(res)
df_results = pd.DataFrame(results).sort_values(["test", "train"], ascending=False)
df_results.head(10)Závislost úspěsnosti modelu (dle zvolené metriky) na hodnotě příslušného hyperparametru si zobrazíme v grafu.
import seaborn as sns
import matplotlib.pyplot as plt
def zobraz_model(model_name, ax, logx=False):
sns.lineplot(x="param", y="train", data=df_results[df_results["model"]==model_name],
markers=True, label="train", ax=ax)
sns.lineplot(x="param", y="test", data=df_results[df_results["model"]==model_name],
markers=True, label="test", ax=ax)
ax.set_title(model_name.capitalize())
if logx:
ax.set(xscale="log")
fig, axs = plt.subplots(ncols=4, figsize=(16,4))
zobraz_model("nearest neighbors", axs[0])
zobraz_model("tree", axs[1])
zobraz_model("random forest", axs[2])
zobraz_model("SVC", axs[3], logx=True)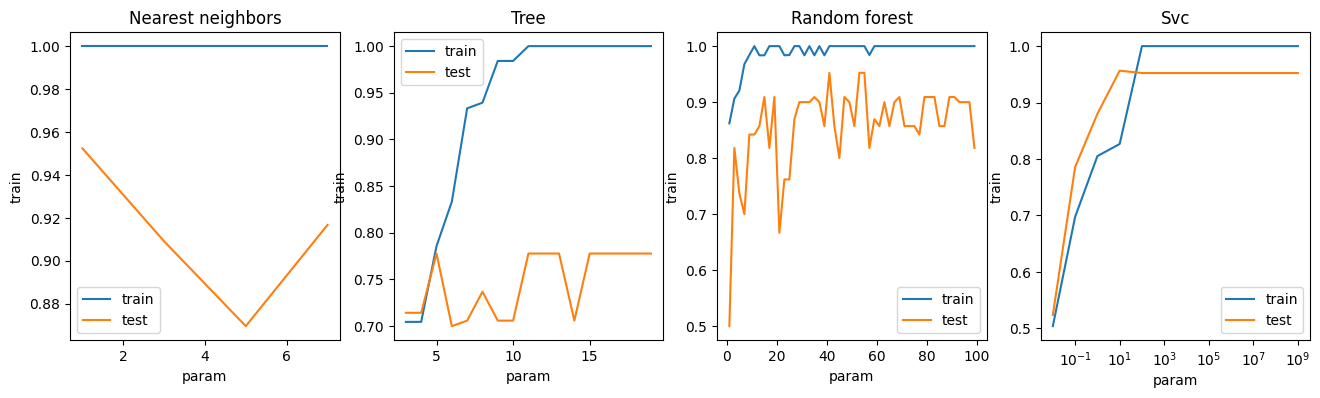
Úkol 6:¶
Vyber si model, který se na validační množině jeví jako nejlepší. Vyzkoušej jej na testovací data.
# načtení data
test_data = read_fish_data("static/fish_data_test.csv")
y_real_test = test_data["druh"] == "Okoun"
y_real_test = y_real_test.astype(int)
X_real_test = test_data.drop(columns=["ID", "druh"])
X_real_test = scaler.transform(X_real_test)# predikce
model = models[("SVC", 10**4)]
test_pred = model.predict(X_real_test)df_compare = (
pd.DataFrame()
.assign(druh=y_real_test)
.assign(predikce=test_pred)
)
df_compare["spravne"] = (df_compare["druh"] == df_compare["predikce"]).replace({True: "OK", False: ":("})
df_compare = df_compare.replace({True: "Okoun", False: "Ostatní"})
display(df_compare.sample(10))
print(f"Počet chyb: {sum(y_real_test != test_pred)}")
print(f"Úspěšnost: {100*sum(y_real_test == test_pred)/len(y_real_test):.2f} %")from sklearn.metrics import precision_score
precision_score(y_real_test, test_pred)0.8571428571428571from sklearn.metrics import recall_score
recall_score(y_real_test, test_pred)0.8571428571428571f1_score(y_real_test, test_pred)0.8571428571428571Bonus: Klasifikace do více tříd¶
Ukažme si pro úplnost, jak na klasifikaci do více tříd.
data = read_fish_data("static/fish_data.csv")
data.sample(10)Jako výstup vezmeme tentokrát sloupec druh, tak jak jej máme. Dělení na trénovací a validační data je stejné, jak ho známe.
y = data["druh"]
X = data.drop(columns=["druh", "ID"])
X_train_raw, X_test_raw, y_train, y_test = train_test_split(X, y, stratify=y)scaler = StandardScaler()
X_train = scaler.fit_transform(X_train_raw)
X_test = scaler.transform(X_test_raw)Vezměme klasifikátor, u binární klasifikace se osvědčil SVC, tak u něj zůstaneme. Vhodné hyper-parametry nám tentokrát spadly z nebe, už jsme je pro vás vyladili.
klasifikator = SVC(class_weight="balanced", probability=True, C=10**5)
klasifikator.fit(X_train, y_train)A máme naučeno, můžeme predikovat.
y_pred = klasifikator.predict(X_test)
y_predarray(['Parma', 'Okoun', 'Štika', 'Šprota', 'Okoun', 'Cejn', 'Okoun',
'Okoun', 'Cejn', 'Cejn', 'Cejn', 'Šprota', 'Okoun', 'Okoun',
'Okoun', 'Štika', 'Parma', 'Štika', 'Okoun', 'Okoun', 'Okoun',
'Okoun', 'Cejn', 'Cejn', 'Cejn', 'Okoun', 'Plotice', 'Okoun',
'Štika', 'Šprota', 'Síh'], dtype=object)Jak vidíte, klasikátor pro každý řádek validačního datasetu vrátil název třídy.
from sklearn.metrics import accuracy_score
100 * accuracy_score(y_test, y_pred)87.09677419354838Máme klasifikováno téměř 84% validačních vzorků, to vypadá slibně. Podívejme se ale na matici záměn (confusion matrix), ta nám přinese více informace.
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_predictions(
y_test, y_pred, labels=klasifikator.classes_
);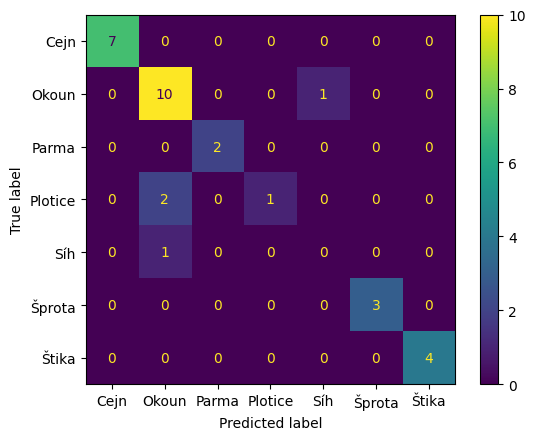
Matice záměn nám prozradila, na kterých třídách klasifikátor chybuje a jak. Např. Jeden okoun byl klasifikován jako síh a jeden síh jako okoun. Největší problém je s ploticemi, dvě z nich byly klasifikovány jako okoun.